Load Balancing is a key concept in distributed systems, it is one of the challenging problem to make sure there is equal distribution, hashing is important to achieve this and consistent hashing is one of the solid ways to do it What is Hashing? Hashing is the process of mapping one piece of data. A …
Load Balancing is a key concept in distributed systems, it is one of the challenging problem to make sure there is equal distribution, hashing is important to achieve this and consistent hashing is one of the solid ways to do it
What is Hashing?
Hashing is the process of mapping one piece of data. A function is usually used for mapping objects to hash code known as a hash function.
For example, a hash function can be used to map random size strings to some fixed number between 0 … N. Like
“abc” -> 123
Load Balancing
Load balancing is about distributing a set of tasks over a set of resources. For example, we use load balancing to distribute the API requests to web server instances.
Mod-n Hashing
In this technique, each key is hashed using a hashing function to transform an input into an integer. Then, we perform a modulo based on the number of nodes.

The benefit of this approach is its statelessness. We don’t have to keep any state to remind us that request2 was routed to node 1. But things would change we add or remove a node.

This results in lots of performance issues, because now requests will move to other nodes and there will be lots of caches miss, to handle this we use consistent hashing.
Consistent Hashing
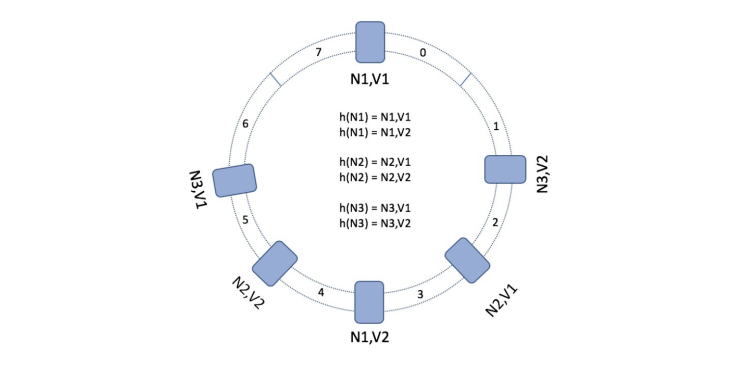
Its a technique, released in a paper by Karger in 1977 that works on fixed keys-slots ring algorithm to find the node, in the following example its just 8 portions ring, in real world example it could be a lot bigger.

We map our nodes/server on this ring using a hash function, in the following case, there are three nodes.

When it receives the request, it gets the hash of the requests and checks the ring clock-wise and routes the request to first node it finds in the range. Lets take example of three requests
f(request1) = 1
f(request2) = 4
f(request3) = 6
so these requests will be handled as following

Request1 will be handled by N2, request2 by N3 and request3 by N1, so far so good now lets suppose we need to add a new node between N2 and N3 to handle more requests.

Now request2 will route to N4 instead of N3, rest is all unchanged, which is great but you will analyze that traffic won’t be evenly distributed to all nodes another case would be if N2 is crashed or removed, then all requests will route to N4 which will eventually overload N4, so solve this virtual nodes are created and multiple hashing functions are used to get different indices for nodes as following

In a excellent consistent hashing algorithm only 1/n keys are mapped again where n is number of nodes. O(1) to add or remove nodes.



