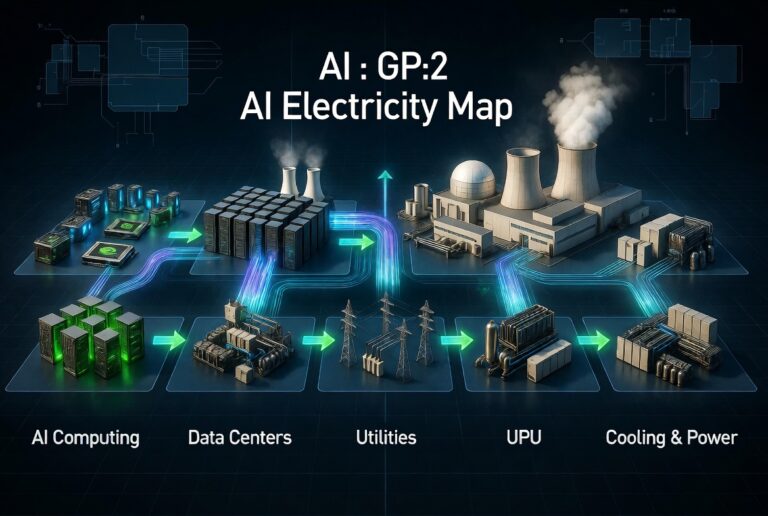
Everyone is trading AI. Almost nobody can draw the power stack underneath it. Here’s the map. The stack GPUs / accelerators ↓ AI infrastructure & neoclouds ↓ Data centers ↓ Utilities / grid ↓ Nuclear + uranium ↓ Cooling, electrical gear, power systems In AlphaOS, this isn’t a vibe — it’s a graph: Full industry …
Kafka is widely used message broker especially in distributed systems, many ask this question that why Kafka is preferred over other available message brokers. There is no clear answer to this question instead it depends on your own requirements. Here we will discuss fundamentals of Kafka which you should know to get started. What is …